 During the past few months I have spend a considerable amount of time looking at various storage related topics. Among others I discussed Web Scale technology as part of converged and software defined architectures, with Nutanix being one of the main vendors, next I also took a, somewhat, deeper dive into the wondrous world of IOPS where I talked about some of their characteristics and ways to potentially enhance performance and the end user experience, which are still two of the main concerns when dealing with these bad boys. Throughout this article I want to take a closer look at some of the differences between block vs file level storage, the accompanying file systems, the different protocols used, potential block sizes and some of the characteristics of VMware VMFS in particular.
During the past few months I have spend a considerable amount of time looking at various storage related topics. Among others I discussed Web Scale technology as part of converged and software defined architectures, with Nutanix being one of the main vendors, next I also took a, somewhat, deeper dive into the wondrous world of IOPS where I talked about some of their characteristics and ways to potentially enhance performance and the end user experience, which are still two of the main concerns when dealing with these bad boys. Throughout this article I want to take a closer look at some of the differences between block vs file level storage, the accompanying file systems, the different protocols used, potential block sizes and some of the characteristics of VMware VMFS in particular.
Key components
As we all know, when dealing with (virtual) desktop infrastructures (although VDI probably a bit more then HSD) the configuration and (fine) tuning of the underlying storage platform and the Hypervisor on top of that both play an important role with regards to overall performance and thus the end user experience. I thought this article would be a nice addition to some of the other topics I already highlighted during the past few months. Of course it also helps that I recently decided to update my ‘old’ VMware VCP 4 credential which got me back on Google reading several blogs and related articles as well as using my personal Pluralsight (some great content on there by the way) account to get me started. I know I’m not the first to touch the subject, or subjects, and I’m sure I won’t the last, but that doesn’t stop me from summarizing and sharing some of my findings. No matter what kind of environment we want to build we’re lost without proper basics like networking and storage, that’s where it all starts. Nowadays I think it is also safe to state that a Hypervisor is also a permanent piece of the puzzle, although there will always be exceptions.
DAS, SAN, NAS, converged
I’ll leave networking out of it for now and primarily focus on the storage components and concepts involved. When it comes to storage we have a few options, although in most cases a lot will depend on what the customer already has in place, but for now let’s assume that we can pick whatever we want. We have DAS (Direct Attached Storage), SAN (Storage Area Network), NAS (Network Attached Storage), several ‘filer’ solution offering both block and file level storage, and finally a few converged infrastructure manufactures to choose from like HP Moonshot, EMC and Cisco’s vBlock and of course Nutanix with its more software defined approach. With enterprise infrastructures in mind we probably won’t spend to much time looking at DAS solutions (unless it’s combined with some kind of converged and or software defined architecture, which are primarily build around local direct attached storage).
In fact, even existing (over tree to four years and older) SAN and or NAS solutions are rapidly being driven into the legacy corner. Fortunately nowadays there are several SSD and or Flash based (caching) solutions on the market which can help speed to up our slightly older storage infrastructures, which is probably why they’ll be around for many more years to come I’m sure. Next to that, most converged and software defined architectures are able to use older SAN and or NAS solutions, combined with their ‘own’ build-in storage, for archive or data tiering purposes for example.
All these storage solutions have one thing in common, they all offer either block or file level based storage (some do both) which can be leveredged by both physical and virtual machines.
As far as Hypervisors go, I’ll keep it short and stick to Microsoft Hyper-V and VMware vSphere as you’ll notice throughout the article.
Last but not least, we also have to consider the file system, Windows NTFS or VMware VMFS for example, that must be installed on the virtual or physical machine needed to read and write data from and onto the underlying storage layer.
Let’s start by having a closer look at some of the differences between block and file level based storage and the protocols used to read and write data for both.
Block based storage
Block based storage is primarily used on Storage Area Networks (SAN’s) and accessed through either iSCSI or Fibre Channel. Simply put, it starts out with a bunch of physical disks from which so called raw storage volumes are created, probably better known as LUN’s or Logical Unit Numbers in full. Next, these LUN’s are presented to a physical host (or virtual using RDM, see below) running Windows for example, which will see and use each LUN as a separate individual hard drive. It will than need to be formatted with a file system like NTFS in the case of Windows, or VMFS if we’re dealing with a VMware ESXi host.
Raw Device Mapping
As mentioned raw storage, or raw storage volumes (represented by LUN’s) are volumes without a file system, like NTFS or VMFS, configured on them. However, using something called a Raw Device Mapping we can directly connect a raw storage volume to a virtual machine without the need to install a file system (NTFS, VMFS etc.) on it first. Using a block based raw volume, you’re basically using a blank hard drive with which you can do anything.
Some pros and cons
 SAN’s are well know for their flexibility and as such implemented on large scale, however, they also tend to be quite expensive and can be complex to manage. When implementing a new, or upgrading an existing, SAN environment, you will have to deal with not only the physical underlying disks and the RAID configurations that come with them, but you’ll also need to manage all LUN’s created and assigned to the various host systems (on a per host basis) this isn’t a task to be taken lightly. That’s why most larger and or mid-sized companies have their own dedicated storage teams to handle day to day operations. Also, with SAN’s come additional infrastructural components like SAN switches and HBA’s to direct traffic to and from your storage network. Even when using iSCSI, which can also function with ‘standard’ Ethernet NIC’s, you will probably want to invest in dedicated iSCSI HBA’s to boost performance. And finally all this infra needs to configured, managed and monitored as well.
SAN’s are well know for their flexibility and as such implemented on large scale, however, they also tend to be quite expensive and can be complex to manage. When implementing a new, or upgrading an existing, SAN environment, you will have to deal with not only the physical underlying disks and the RAID configurations that come with them, but you’ll also need to manage all LUN’s created and assigned to the various host systems (on a per host basis) this isn’t a task to be taken lightly. That’s why most larger and or mid-sized companies have their own dedicated storage teams to handle day to day operations. Also, with SAN’s come additional infrastructural components like SAN switches and HBA’s to direct traffic to and from your storage network. Even when using iSCSI, which can also function with ‘standard’ Ethernet NIC’s, you will probably want to invest in dedicated iSCSI HBA’s to boost performance. And finally all this infra needs to configured, managed and monitored as well.
Backing up your backend workloads form block based storage is, or can be, business as usual, so to speak. Since LUN’s are seen and treaded as ‘normal’ hard drives, formatted with a file system like NTFS when using Windows as the underlying OS, third party, or native OS, backup tooling can be used to backup the LUN’s as if they where physical local disks, the host machine won’t know the difference. Of course you might handle things differently when working exclusively with virtual machines, but I’ll leave that up to you to decide.
File based storage
Now that we have had a closer look at block based storage, what about file level? File level storage is mostly used with Network Attached Storage devices, or NAS in short, and unlike SAN’s they tend to be easier to initially set up and manage on a day to day basis. File level storage, or Network Attached Storage (in most cases) is nothing more than a repository (also a bunch of underlying physical disks) where raw data can be stored. In general they provide a lot of space at much lower costs per GB than a SAN can offer.
File level storage is normally accessed using CIFS shares through a UNC path or a share mapped to a drive letter, using protocols like SMB and CIFS when it comes to Windows, or NFS if using VMware or some other Linux based variant. This is also where its simplicity shines as apposed to block level storage, you don’t have to configure and format separate hard disks and than copy or store your data on there, instead it’s available directly from the network. Of course you will still need to set up and configure the various storage repositories (shared folders) on the NAS itself, and although the way you go about this will slightly differ per type (vendor specific in most cases) of NAS you purchase, in most cases this will be a relatively straightforward process.
Some pros and cons
 Where block based storage tightly integrates with the Operating System installed on the host, as described earlier, NAS devices have their own Operating System which you need to get familiar with, something to keep in mind if you’re new to file level storage or NAS devices in general. Also, with block level storage you will probably use Windows in combination with Active Directory for example when it comes to managing permissions and authentication, basically nothing new. With file level storage, or NAS devices, this might work a bit different. Although most file level storage devices will integrate with your existing authentication and or security systems, more often than not, user access and permission management will (also) need to be configured on the file level storage device itself. On the other hand, if relatively simple (mass) storage is what you need and performance isn’t that big of an issue, than file level storage is definitely the way to go. Because they have their OS and are per-configured out the box, you’ll have them set up and running within minutes instead of hours, days, or sometimes weeks even, when compared to its more complex bigger SAN brother.
Where block based storage tightly integrates with the Operating System installed on the host, as described earlier, NAS devices have their own Operating System which you need to get familiar with, something to keep in mind if you’re new to file level storage or NAS devices in general. Also, with block level storage you will probably use Windows in combination with Active Directory for example when it comes to managing permissions and authentication, basically nothing new. With file level storage, or NAS devices, this might work a bit different. Although most file level storage devices will integrate with your existing authentication and or security systems, more often than not, user access and permission management will (also) need to be configured on the file level storage device itself. On the other hand, if relatively simple (mass) storage is what you need and performance isn’t that big of an issue, than file level storage is definitely the way to go. Because they have their OS and are per-configured out the box, you’ll have them set up and running within minutes instead of hours, days, or sometimes weeks even, when compared to its more complex bigger SAN brother.
Backup and restores of file level storage might take a bit more consideration because of their non standard Operating Systems as mentioned above. But don’t worry, it usually isn’t that complex. And remember, when in doubt just ask one of your geek colleagues, every company has a few of those right?
All in all
To summarize, both have pros and cons and as always, a lot will depend on your specific needs, including your budget. Where block level storage is very flexible and offers high performance (depending on use case) but comes at a prize of more complex management, harder to set up and is more expensive etc. file level storage is easy to set up and manage and it offers relatively cheap mass storage compared to block level, but… performance could be an issue and user access and permissions need to be configured on the file level storage device itself which might need a little getting used to.
Some exceptions
At this time I’d like to point out that the above described characteristics for both solutions do not always apply, it greatly depends on the type (or vendor) of Hypervisor used in combination with either block or file level storage. For example, when block level storage is used combined with VMware ESXi VMFS LUN’s need to be accessed through the Hypervisor which implies a performance degradation, using NFS, and thus file level storage, it will communicate directly with the host. Hyper-V doesn’t have that problem with block level, however, the same applies to Hyper-V when using file level storage, it than uses the CIFS protocol to access its virtual machine files which is relatively insufficient. Check out this article, it summarizes a great deal of the pros and cons when it comes to using either Hyper-V and VMware ESXi in combination with block or file level storage.
http://www.computerweekly.com/feature/Block-vs-file-for-Hyper-V-and-VMware-storage-Which-is-better
Nutanix
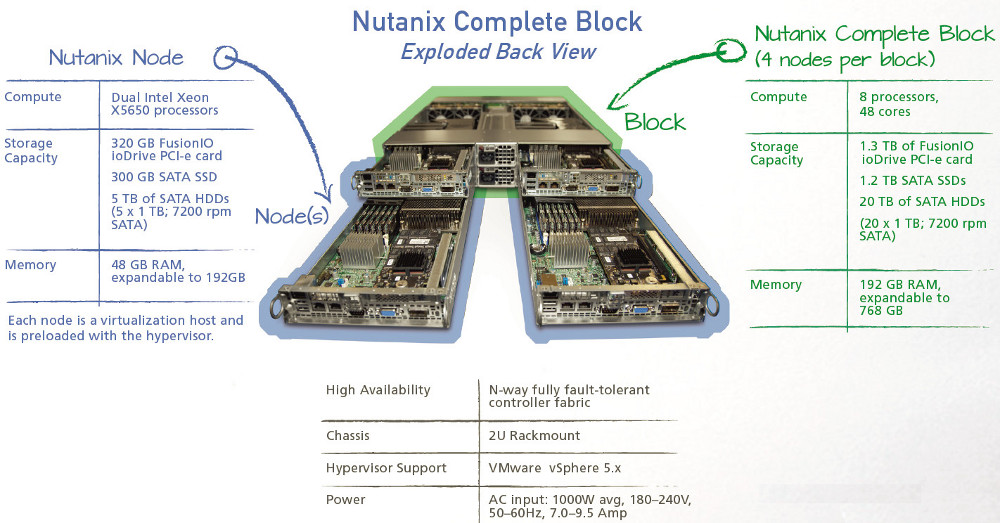 There they are again :-) Just as with every other converged solution, the underlying storage will also need to be formatted and presented to the virtual machines in some way. Since Nutanix has is own extensive database filled with technical documentation I won’t even bother to try and describe their way of handling this. The below comes from one of their own technical guides, one of many which they provide on Nutanix.com
There they are again :-) Just as with every other converged solution, the underlying storage will also need to be formatted and presented to the virtual machines in some way. Since Nutanix has is own extensive database filled with technical documentation I won’t even bother to try and describe their way of handling this. The below comes from one of their own technical guides, one of many which they provide on Nutanix.com
Storage Pools
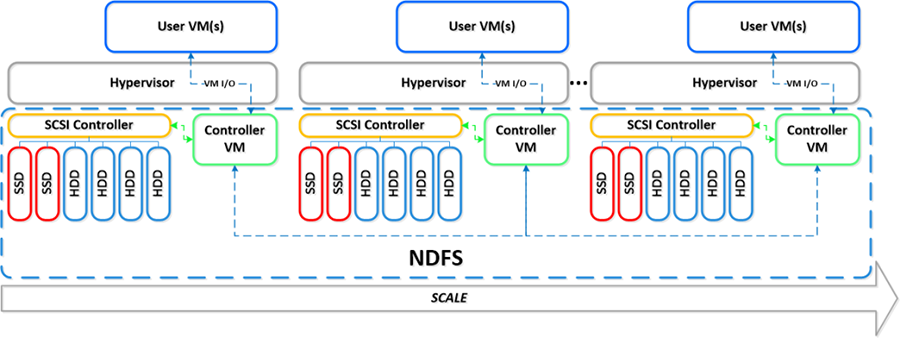
Storage pools are groups of physical disks from one or more tiers (see Creating a Storage Pool). Storage pools provide physical separation between virtual machines because a storage device can only be assigned to a single storage pool at a time. Nutanix recommends creating a single storage pool to hold all disks within the cluster. This configuration, which supports the majority of use cases, allows the cluster to dynamically optimize the distribution of resources like capacity and IOPS. Isolating disks into separate storage pools provides physical separation between VMs, but can also create an imbalance of these resources if the disks are not actively used. When you expand your cluster by adding new nodes, the new disks can also be added to the existing storage pool. This scale-out architecture allows you to build a cluster that grows with your needs.
Storage Containers
A container is a subset of available storage within a storage pool (see Creating a Container). Containers hold the virtual disks (vDisks) used by virtual machines. Selecting a storage pool for a new container defines the physical disks where the vDisks will be stored. Nodes in the Nutanix cluster can mount a container as an NFS datastore or iSCSI target to provide shared storage for VM files. This storage is thinly provisioned, which means that storage is allocated to the container only as needed when data is written, rather than allocating the total maximum capacity when the container is created. One of the options at the container level is to enable compression either inline (as it is written) or after it is written
vDisks
A vDisk is a subset of available storage within a container, and vDisks provide storage to virtual machines. If the container is mounted as an NFS volume, then the creation and management of vDisks within that container is handled automatically by the cluster. It may be necessary to enable iSCSI access for a subset of your VM workloads. To provide iSCSI access at the VM or host level, you can create vDisks of one of two types:
- RDM, which can be directly attached to a virtual machine as an iSCSI LUN to provide high-performance storage.
- VMFS, which can be mounted as a VMFS datastore to provide additional shared storage within the cluster.
Datastores
A datastore is a logical container for files necessary for VM operations. Nutanix provides choice by supporting both iSCSI and NFS protocols when mounting a storage volume as a datastore within vSphere. NFS has many performance and scalability advantages over iSCSI, and it is the recommended datastore type.
NFS Datastores. The Nutanix NFS implementation (NDFS) reduces unnecessary network chatter by localizing the data path of guest VM traffic to its host. This boosts performance by eliminating unnecessary hops between remote storage devices that is common with the pairing of iSCSI and VMFS. To enable vMotion and related vSphere features (when using ESXi as the hypervisor), each host in the cluster must mount an NFS volume using the same datastore name. The Nutanix web console and nCLI both have a function to create an NFS datastore on multiple hosts in a Nutanix cluster.
 VMFS Datastores. VMFS vDisks are exported as iSCSI LUNs that can be mounted as VMFS datastores. The vDisk name is included in the iSCSI identifier, which helps you identify the correct LUN when mounting the VMFS volume. VMFS datastores are not recommended for most VM workloads. To optimize your deployment, it is recommended that you discuss the needs of all VM workloads with a Nutanix representative before creating a new VMFS datastore within the cluster.
VMFS Datastores. VMFS vDisks are exported as iSCSI LUNs that can be mounted as VMFS datastores. The vDisk name is included in the iSCSI identifier, which helps you identify the correct LUN when mounting the VMFS volume. VMFS datastores are not recommended for most VM workloads. To optimize your deployment, it is recommended that you discuss the needs of all VM workloads with a Nutanix representative before creating a new VMFS datastore within the cluster.
File Systems and block sizes
Now that we’ve discussed some of the storage related characteristics I’d like to spend a few minutes on file systems and block sizes. When we use block level storage, as discussed, raw storage volumes get presented to the host Operating System where they get formatted with a file system of which Windows and VMware are probably the best known ones. Windows offers NTFS and VMware uses VMFS. This comes from Microsoft.com with regards to NTFS:
Windows NTFS
All file systems that are used by Windows organize your hard disk based on cluster size (also known as allocation unit size). Cluster size represents the smallest amount of disk space that can be used to hold a file. When file sizes do not come out to an even multiple of the cluster size, additional space must be used to hold the file (up to the next multiple of the cluster size).
If no cluster size is specified when you format a partition, defaults are selected based on the size of the partition. These defaults are selected to reduce the space that is lost and to reduce the fragmentation that occurs on the partition. See the table below for an overview:
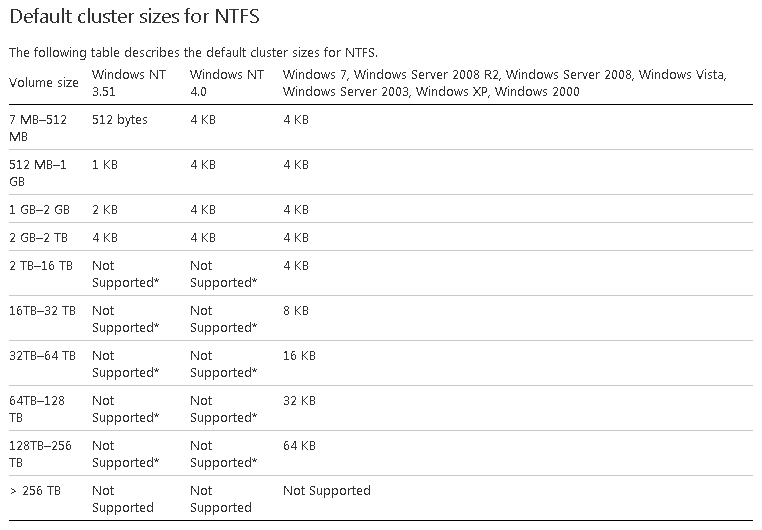 As you can see the cluster size a.k.a. block size, directly influences the maximum volume size, although the step from 16TB to 32TB and beyond is massive, and probably not one you will have to worry about any time soon. However data block size can also play an important role when it comes to calculating your inputs and outputs per second, or IOPS. Let me rephrase that, when someone states that their storage solution can do a million IOPS, ask them which block size was used. Of course this is only one of many questions that need to be asked when calculation IOPS, but an important one never the less! Also see one of my previous articles dedicated to the IOPS debacle, you’ll find it here.
As you can see the cluster size a.k.a. block size, directly influences the maximum volume size, although the step from 16TB to 32TB and beyond is massive, and probably not one you will have to worry about any time soon. However data block size can also play an important role when it comes to calculating your inputs and outputs per second, or IOPS. Let me rephrase that, when someone states that their storage solution can do a million IOPS, ask them which block size was used. Of course this is only one of many questions that need to be asked when calculation IOPS, but an important one never the less! Also see one of my previous articles dedicated to the IOPS debacle, you’ll find it here.
VMware VMFS
As of vSphere ESXi5 VMware introduced VMFS5 which builds on top of its previous file system VMFS3. However, this doesn’t necessarily mean that you will have to use VMFS5, you can still use VMFS3 just as easy. For example, when you update your ESXi hosts to vSphere 5, 5.1 or 5.5 for that matter, you can still continue to use VMFS3. In fact, your datastores aren’t updated automatically, this is something you will have to manually. Keep in mind that when updating your VMFS3 data stores, they will continue to use the block size initially configured under VMFS3, I will elaborate a bit more on this in a minute. If you choose not to upgrade your VMFS datastores you will miss out on a ton of additional features and enhancements introduced with VMFS5, see the link mentioned below for some more information.
VMFS3 offered us four different block sizes (also referred to as file blocks) to choose from:
- 1MB block size – maximum file size: 256 GB;
- 2MB block size – maximum file size: 512 GB;
- 4MB block size – maximum file size: 1 TB;
- 8MB block size – maximum file size: 2 TB – 512 bytes.
VMFS5 only offers only one block size:
- 1 MB block size – maximum file size: 64 TB.
Sub blocks you say?
But wait… There is more. Both VMFS3 and VMFS5 also offer so called sub-blocks, these blocks are used to store files and directories smaller than 64KB, in the case of VMFS3, or 8KB, when using VMFS5. This saves space because this way smaller files don’t have to be stored using a full (file) block, which can range from 1 to 8 MB. It works like this, as mentioned, and depending on the version of VMFS that is in place the system either uses 64KB or 8KB sized sub blocks. When sub blocks are used for storing smaller files it will always ‘just’ use a single sub block, as soon as the file is, or grows, larger than the size of 1 sub block (64 or 8KB) it will continue to use the ‘normal’ configured (file) blocks as highlighted above.
So it will NOT use multiple sub blocks to store files smaller than the actual configured VMFS (file) block size, which would be 1 MB with VMFS5. An example, let’s say that VMFS5 is configured, meaning a (file) block size of 1 MB accompanied by 8KB sub blocks. Now when the system needs to store a file of 64KB, which is way smaller than the default (file) block size, it WON’T store the file using 8 times 8KB sub blocks, no, it will simply store the file within a ‘normal’ 1 MB (file) block. Only if the file is actually 8KB or smaller it will use a sub block to store it.
Be aware that the number of sub blocks is limited, VMFS3 only has 4000 available where as VMFS5 has 8 times as much, 32000.
One more thing…
Before I leave you there’s one other thing I’d like to point out with regards to datastores and block sizes. When using VMFS5 on multiple hosts, you need to make sure that all your hosts run at least ESXi version 5 or higher. Where VMFS3 is forwards (up to version 5) and backwards compatible, VMFS5 isn’t.
Check out this VMFS5 upgrade considerations .PDF document by VMware:
http://www.vmware.com/files/pdf/techpaper/VMFS-5_Upgrade_Considerations.pdf
Reference materials used: VMware.com, Techrepublic.com, Wikipedia.org and Computerweekly.com


